
It is difficult to perceive risks and opportunities related to information if we cannot estimate its value. In this article I will try to present some approaches that could be used to estimate information value. The article is based on the presentation @ViktorPolic has given as a guest lecturer to master students at School of Economics and Management of Geneva University.
Traditional value management, based on the accounting practice, valuates all assets in their monetary equivalents. That facilitates bookkeeping, financial management and auditing. Information assets fall into category of intangible assets. Usually accounting practice refers to trade secrets, patents and trademarks as intangible corporate assets. Another category of intangible assets is intellectual capital. It includes those aspects of corporate value such as know-how and individual skills, i.e. “what leaves company everyday after working hours”. But this value is in human assets. In order to link intellectual capital to intangible corporate assets such as information assets we need to segregate objective and subjective aspects of information value measurement. Without taking intellectual capital into information value formula it would remain incomplete and cannot satisfy needs of measuring values related to digital transformation, big data analytics, machine learning, artificial intelligence, cyber risks?

William Thomson, 1st Baron Kelvin, in his lecture on “Electrical Units of Measurement” published in Popular Lectures Vol. I, p. 73 in 1883 wrote:
“When you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot measure it, when you cannot express it in numbers, your knowledge is of a meager and unsatisfactory kind: it may be the beginning of knowledge, but you have scarcely, in your thoughts, advanced to the stage of science.”
So how can we measure value of information?
Let’s define information before attempting to measure its value.
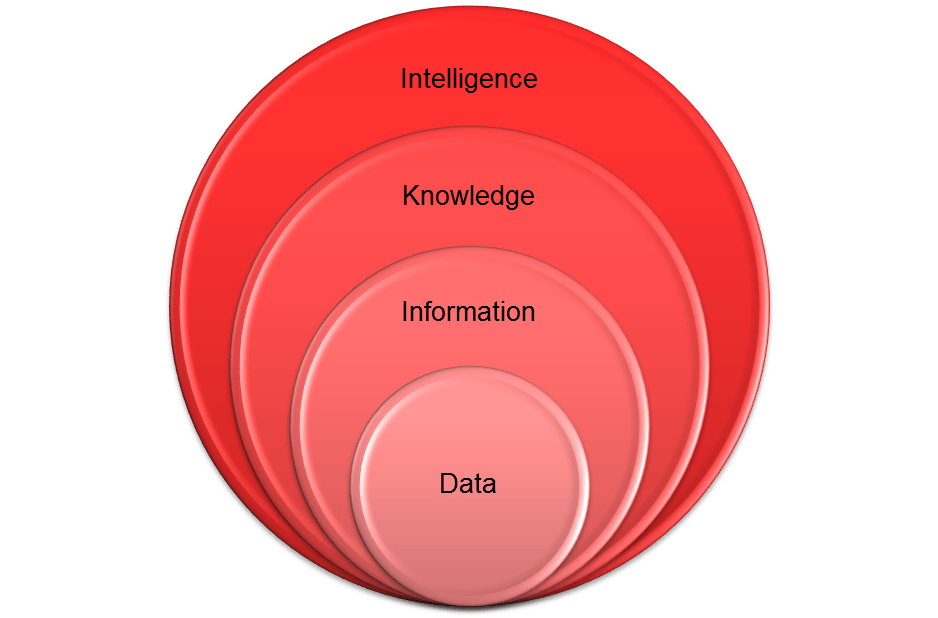
As illustrated below, information is at the higher level of abstraction from data. While data represents values of variables and encoded facts, information is derived from data and complies with meanings (semantics). Information is therefore subjective. Knowledge is even more abstract as it is derived from information. Let’s leave the knowledge aside for now.

Information theory introduces the notion of entropy as the average amount of information contained in a message. It is a measure of uncertainty about the source of data. Shannon’s information content is used to quantify the amount of information associated with the outcome of a random variable. Information in this context does not relate to the meanings (semantics) derived from data.
Shannon’s entropy is best describing the discrete knowledge when the outcome is selected from a given finite set of possible outcomes.
While the work of Shannon helped revolutionizing telecommunications, compression, encryption, authentication, it is limited to linear communication. The network of networks, the Internet, represents nonlinear media so Shannon’s information content has to be expanded to represent uncertainties of nonlinear media.
Warren Weaver proposed using computers to translate natural languages. He introduced tripartite analysis of information:
- Technical problems concerning the quantification of information – dealt with by Shannon’s theory
- Semantic problems relating to meaning and truth – crucial for systematizing the knowledge
- “Influential” problems concerning the impact and effectiveness of information on human behavior – crucial for creating business value
Semantic classification has practical importance in the process of identifying and mapping corporate information to business strategy and related value. Luciano Floridi proposes the following information map relating semantics to mathematical theory of communication:
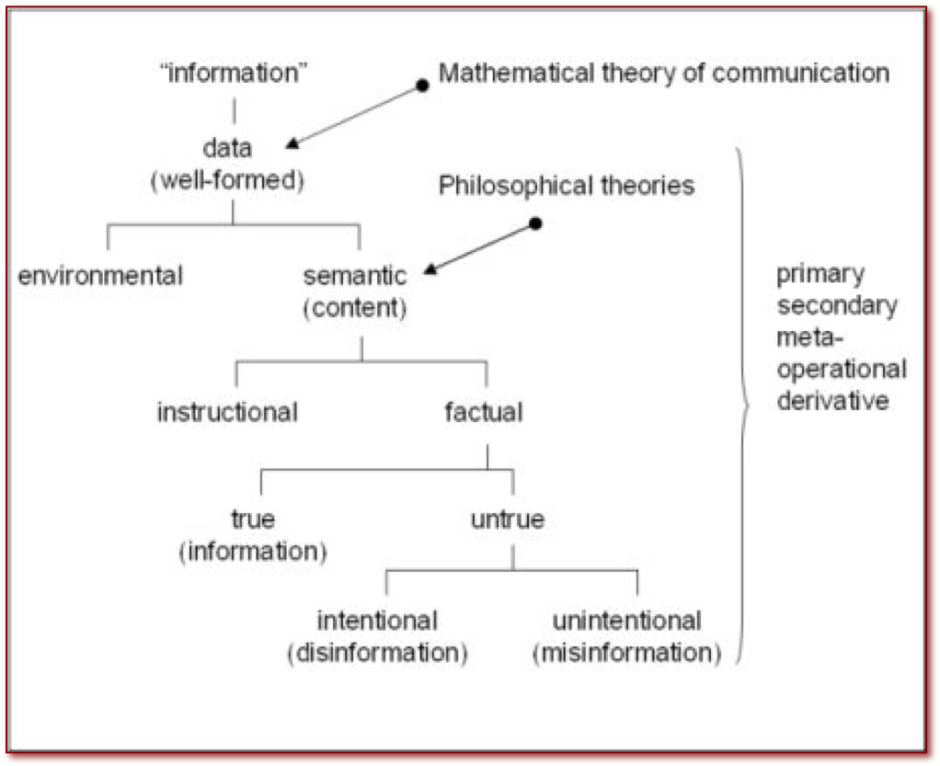
Floridi goes further into proposing the general definition of information which includes a truth-condition:
“σ is an instance of information, understood as semantic content, if and only if:
- σ consists of one or more data
- the data in σ are well-formed
- the well-formed data in σ are meaningful”
Considering data organization, ensuring data quality, data accuracy and its relevance for particular business purpose is crucial for general discussion on information value. Data abundance does not automatically imply its high business value. Business decision makers should consider residual value after investing into data verification, cleansing, structural analysis, enrichment, transformation, and other data management processes. In other words, data is potentially an information ore but its business value must be carefully estimated taking into consideration costs involved in its complete transformation process.
Let’s apply some lessons learned from the .COM bubble into this discussion on information value in order to avoid .BigData bubble. At the peak of the .COM business hype in 2001 Michael Porter observed that only those Internet companies that adapt their longer term strategy and that differentiate from best-practice driven business will prosper. He declared that best practice leads to competitive convergence. Porter continues that the Internet has turned IT into a far more powerful tool for strategy but companies need to see the bigger picture rather than just considering the operational effectiveness. Companies need to adapt their value chain for sustainable competitive advantage.
Already in 1995 Rayport and Sviokla published an article on the importance of exploiting a “virtual value chain” alongside the physical value chain. They have recognized importance of digital transformation for more effective and efficient value-adding. That was more than 30 years ago, much before data lakes, machine learning based data analytics and commercially available artificial intelligence. During the last three decades we have learned that information is not only support for physical value. Digital transformation has created new digital marketplaces and interconnected them into “the Web 2.0”. While the “Web 1.0” represented exploitation of multimedia contents in the interconnected World, “Web 2.0” recognized value of transforming data into information on the global scale.
We live now in the “Web 3.0” era. It is based on knowledge management. As stated above, knowledge is indirectly derived from information. It’s the higher abstraction of data than information. Kimiz Dalkir defines knowledge management as a systematic coordination of an organization’s people, technology, processes, and organizational structure in order to add value through reuse and innovation. He highlights importance of corporate memory created though sharing, applying knowledge and collecting lessons learned.
Not all knowledge is simple to manage. While explicit knowledge is tangible and easier to share such as document archives, video and audio recording and in other forms and collections of expressions in recognized codes and notations, tacit knowledge is intangible and subjective. Tacit knowledge was introduced by Michael Polanyi. For companies tacit knowledge represents intellectual capital. While competencies of people are considered at tactical management levels, capabilities are of strategic importance.
This leads into intelligence as the ultimate data abstraction layer. Intelligence represents ability to perceive and retain knowledge. This definition relates to human intelligence.
Business intelligence refers to technologies and processes that collect, store and analyze data produced by company’s activities. While data queries and related reporting (also referred to as data mining) support knowledge management, advanced data analytics supports business intelligence. Data mining focuses on looking for known patterns in data. More precisely it is called descriptive data mining or knowledge discovery. Advanced analytics consists of discovering and validating new previously unknown patterns in data. It is vital to reiterate importance of data quality in all of its attributes (time, contents and form) for business intelligence accuracy. Adequate data optimization for different types of data mining is important for efficiency. Online transactional processing (OLTP) is a relational data store optimized (normalized) for transactional activities such as inserts, updates, and deletes. On the other hand, online analytical processing (OLAP) is based on denormalized data structures efficient for data reading. One example of such data structures are multidimensional data stores called cubes. Sometimes multiple cubes are collected within a data warehouse. In cases when there is no solid hypothesis about collected data predictive or prescriptive data mining is used. Predictive data mining is process of deriving a model that can forecast certain response (for example a model for identifying financial transactions with high-risk of being fraudulent). Prescriptive data mining is process of prescribing multiple courses of action and shows likely outcomes. Prescriptive data mining requires actionable data and active feedback.
While historically decision support systems were implemented already back in 60’s, OLAP systems became widely implemented in 90’s. We may argue that OLAP based decision support systems are suitable for implementing explicit knowledge management. For tacit knowledge management an additional subsystem is required to perform reasoning, or inference as described by Edward Feigenbaum. Information systems that consist of knowledge base and inference engine are called expert systems. They were implemented as early as late 50’s for medical research. In 60’s and 70’s expert systems were built in oil exploitation industry, automotive industry, financial industry, aviation, and other. Feigenbaum highlights that early expert systems were limited to the scope of expertise collected within particular area. More recent work on artificial intelligence is focusing on model-based reasoning rather than fuzzy logic and Bayes’ Theorem. We may refer to this method as supervised machine learning. Feigenbaum highlights importance of knowledge reuse and interchange in order to overcome scope limits of specific expertise.
Inference engine evolved into deep-learning engine. Deep-learning is multi-layered system based on artificial neural network architecture. It makes unsupervised learning possible. Such engine is able to perform self-classification of data. It may fulfil Feigenbaum’s vision of the library of the future.
With technological advances of information and communication hardware and software for data storage, communications and distributed data processing, availability of data grows in volume, variety and velocity. This refers to “big data” buzzword. Advances in contextual analytics contribute to more accurate and timely identification of risk and opportunities and prediction of courses of action. This results in proactive rather than reactive business decision making. Terms such as risk intelligence are now used in businesses to describe modern risk analysis expert systems based on external and internal intelligence to provide augmented risk awareness for decision makers. Decision makers in symbiosis with such systems are able to bridge the gaps between tactical and strategic decision making and maximize efficiency of their virtual value chain.

